Documentation Index
Fetch the complete documentation index at: https://domoinc-arun-raj-connectors-domo-479583-raisers-edge-connec.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
はじめに
DataFlowを作成し、SQLクエリを使ってデータを結合および変換します。この方法によるDataFlowの操作は、Magic ETLを使用する場合に比べて技術的な知識を必要としますが、オプションはより幅広くなります。Magic ETL DataFlowの作成については、「Magic ETL DataFlowを作成する」を参照してください。 PDPポリシーが有効の状態で入力DataSetを使ってDataFlowを作成する場合は、以下の条件が少なくとも1つ満たされていないとDataFlowに不具合が発生します。- 自分自身に「管理者」セキュリティプロフィール、または「DataFlowを管理」の許可が有効なカスタマイズされた権限がある。
- 自分自身がDataSetの所有者である。
- 「全ての行」ポリシーに自分のユーザーアカウントが追加されている。これにより、DataSetのすべての行にアクセスできます。
動画 - DataFlowを使用してDataSetを結合する
SQL DataFlowを作成する
**注記:**Redshiftでは、http://docs.aws.amazon.com/redshift/latest/dg/c_unsupported-postgresql-features.htmlに記されているように、ストアドプロシージャはサポートされていません。代替手段として、ストアドプロシージャをサポートするMySQL DataFlowを使用します。
- Domoで、画面上部のツールバーの****[データ]****をクリックします。
- ウィンドウ上部の**[Magic変換]ツールバーの[SQL]**をクリックします。

DataFlowを作成するビューが開きます。 4. DataFlowの名前と詳細を入力します。 5. 以下に従って、目的のDataFlow用の入力DataSetを選択します。
-
- **[DataSetを選択]**をクリックします。
**注記:**DataFlowの入力DataSetは既にDomoに存在するものである必要があります。DataFlowを作成するビューで新しいDataSetをアップロードすることはできません。新規DataSetのDomoへのアップロード方法については、「コネクターでデータに接続する」を参照してください。
 3. **[DataSetを選択]**をクリックします。
3. **[DataSetを選択]**をクリックします。選択したDataSetのタイルが画面に表示されます。DataSetタイルをクリックして、プレビューウィンドウを表示することができます。
-
(オプション)**[列を選択]タブの下で、列名の右側の「x」をクリックすると、DataSetに含めたくない列を削除できます。また、[None]**をクリックすると、すべての列を削除できます。
**[列を追加]ボタンをクリックして該当の列を選択することで、DataSetに個々の列を戻すこともできます。また、[All]**をクリックすると、DataSetにすべての列を戻すことができます。

- DataSetの処理方法を選択します。このメニューでは、すべてのDataSetを処理するか、最後にDataFlowが実行された後に追加された新しい行のみを処理するかを選択できます。
**注記:**この機能は現在ベータ版です。ベータ版を利用するには、担当のカスタマーサクセスマネージャー(CSM)に連絡してください。

-
**[変換を追加]をクリックします。
様々なオプションとともに、[変換]**ダイアログが表示されます。これらのオプションの詳細については、「変換および出力DataSetオプションを理解する」を参照してください。 - SQLコードを入力し、入力DataSetを変換させます。
- **[適用]**をクリックします。
-
**[出力DataSetを追加]をクリックします。
様々なオプションとともに、[出力DataSet]**ダイアログが表示されます。これらのオプションの詳細については、「変換および出力DataSetオプションを理解する」を参照してください。- SQLコードを入力し、入力DataSetをどのように結合させるかを指定します。
**[変換]**ダイアログで入力DataSetを変換した場合は、その変換はここで適用されます。 - (オプション)前の2つのステップを繰り返して、出力DataSetを追加します。
- **[終了]**をクリックします。
- SQLコードを入力し、入力DataSetをどのように結合させるかを指定します。
- **[設定]**ペインでDataFlowをスケジュールします。様々なスケジュールオプションの詳細については、「Advanced DataFlow Triggering」を参照してください。
**注記:スケジュールがまだ指定されていない場合は、DataFlowはデフォルトで手動スケジュールに設定されます。
9. (条件付き)DataFlowをStrictモードで実行する場合は、画面上部の[設定]ボタンをクリックし、[Strictモード]**オプションをオンに切り替えます。
このオプションの詳細については、「Strictモードを理解する」を参照してください。
このオプションの詳細については、「Strictモードを理解する」を参照してください。
 10. (条件付き)以下のいずれかを行い、DataFlowを保存します。
10. (条件付き)以下のいずれかを行い、DataFlowを保存します。
- このDataFlowを出力してDomoで利用できるDataSetにするためのスクリプトを実行する場合は、画面の右上隅にあるオレンジ色の下矢印をクリックし、**[保存して実行]を選択し、必要に応じてバージョンの説明を入力してから[保存]**をクリックして確定します。 これで、DataFlowからDataSetが作成されるプロセスが開始されます。入力DataSetのサイズによって、この作成プロセスは1分から1時間、またはそれ以上かかります。DataSetの生成に加え、DataFlowのカードがData CenterのDataFlowリストに追加されます。
-
このDataFlowを今回だけDataSetに出力せずに保存したい場合は、[保存]をクリックし、必要に応じてバージョンの説明を入力してから、[保存]を再びクリックして確定します。DataFlowのカードがData CenterのDataFlowリストに追加されますが、DataSetは生成されません。DataFlowを実行してDataSetに出力する操作はいつでも行うことができます。これは、DataFlowリストにあるDataFlowのカードにマウスポインターを合わせ、
 をクリックして**[実行]**を選択することで行います。このオプションおよびこのメニューで利用できるその他のオプションについては、本トピックで後ほど説明します。
をクリックして**[実行]**を選択することで行います。このオプションおよびこのメニューで利用できるその他のオプションについては、本トピックで後ほど説明します。
**注記:**DataFlowが正常に実行されたときにDataFlowの出力DataSetが「更新済み」としてマークされないのはなぜかと疑問に思われるユーザーの方が多くいます。これは一般的には、データが実際には変更されていないためです。つまり更新されていません。そのため、DataSetは更新済みとは表示されません。
変換および出力DataSetオプションを理解する
新しい変換を作成すると、表タイプまたはSQLタイプの変換を作成できます。- 表変換では、SELECTステートメントを使用して新しい表が作成され、常に出力表が生成されます。出力表が生成されるため、これらの表にもとづき簡単なインデックスを作成できます。
- SQL変換では、ストアドプロシージャといったSELECTステートメントを通常は含まない表が作成されます。この変換タイプでは出力表は作成されません。
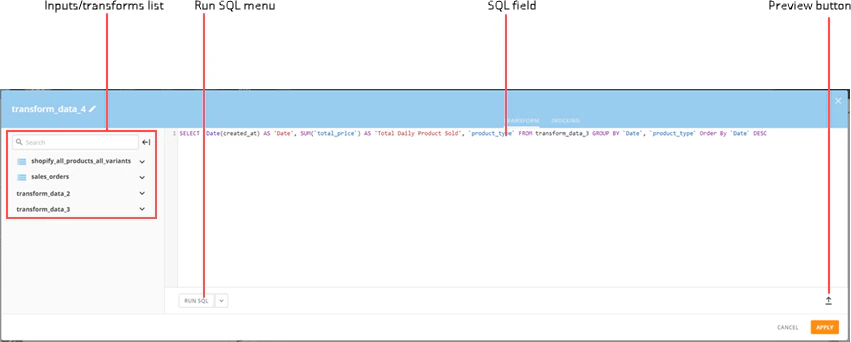
| コンポーネント | 説明 |
|---|---|
| 入力/変換リスト | SQLステートメントを作成する際に活用できるよう、このDataFlowで選択したすべての入力DataSetの名前が表示されます。さらに、以前に作成した変換もここに表示されます。これらの名前は**[変換]および[出力DataSet]ダイアログの両方に表示されます。[変換]ダイアログで1つ以上の入力DataSetを変換した場合、[出力DataSet]**ダイアログで参照した時にその変換は入力DataSetに適用されます。 入力DataSetをクリックすると、DataSet内のすべての列とそのデータタイプ(DECIMAL、TEXT、DATE/TIMEなど)のリストが表示されます。 |
| [SQLを実行]メニュー | 以下のオプションを使用できます。 - - [SQLを実行]:SQLが有効かどうか確認するためのテストを実施することができます。 - [ここまで実行]:この時点までの以前の変換すべてを実行します。 - [EXPLAIN SQL]:SQLのEXPLAIN PLANを表示します。これは、クエリの実行時にデータベースが作成するステップの順序付けられたリストです。このオプションを使用するとクエリを最適化できます。ただし、これらのステップは非常に複雑で専門的なため、この機能は上級ユーザーのみに推奨されます。 **注記:**実行時の効率性向上に必要なインデックスはMySQLによって判断されるため、すべてのインデックス変換がEXPLAIN SQLに表示されるわけではありません。インデックスを実行することで、効率性が低下すると判断される場合もあるためです。 |
| SQLフィールド | 入力DataSetの変換や結合を行うためのSQLコードを作成できます。このフィールドには、コードを書く時に便利な自動入力機能が含まれています。 |
| プレビューボタン | **[SQLを実行]または[ここまで実行]**の選択後に、ペイン下部にプレビューエリアを展開または折りたたみます。 |
データをプレビューする
**[SQLを実行]または[ここまで実行]**の選択後に、変換にプレビューが表示されます。プレビューメニュー**注記:**これらの設定は、変換自体やデータの出力方法には影響しません。プレビュー表での結果の表示方法にのみ影響します。

| コンポーネント | 説明 |
|---|---|
| テキストを表示 | - [デフォルト] - 標準フォントでテキストを表示します。 - [モノスペース] - 文字間隔をより広く取ってテキストを表示します。 |
| Null値の処理 | - [高度] - nullまたは空の文字列を表示して、列に表示する値のタイプを指定します。 - [ベーシック] - 表内の空白セルを表示します(これがデフォルト設定です)。 |
| 10進精度 | - [デフォルト] - DataSetに表示される通りに数値を表示します。 - [設定] - 指定した小数点以下の桁数を表示します。 |
簡単なインデックス作成
インデックスは、表での操作速度を向上させるデータ構造です。簡単なインデックス作成を使用すると、入力DataSetまたは表の変換で1つ以上の列にすばやくインデックスを作成できます。 入力DataSetまたは変換でインデックスを作成するには:- 入力DataSetまたは変換のエディターを開きます。
-
**[インデックス作成中]**タブを選択します。

- インデックスのタイプを選択します。
- インデックスを適用する列を選択します。
- **[終了]**をクリックします。
Strictモードを理解する
Strictモードは、データ変更ステートメントの無効な値や欠損値をMySQLでどのように処理するかを制御します。また、ゼロによる除算、ゼロの日付、日付内でのゼロ値の処理方法にも影響します。詳細については、https://dev.mysql.com/doc/refman/5.6/en/sql-mode.html#sql-mode-strictを参照してください。DataFlow作成のためのベストプラクティス
各DataFlowでは以下の点に注意しましょう。- 変換における各ステップに、記述的な名前をつけること。
- 結合または操作される入力DataSet、および作成されるDataSetの説明を含めること。データの所有者を示すことも必要です。
- 出力DataFlowと同じ名前を付けること(DataFlowの出力はData Center内の独自のDataSetになるため)。これにより、どのDataSetがどのDataFlowによって作成されたかを容易に識別できるようになります。